
가중치 초기화 (Weight Initialization)
17 Mar 2020 | Deep-Learning
이번 게시물은 “밑바닥부터 시작하는 딥러닝”과 “Weight Initialization Techniques in Neural Networks”를 참조하여 작성하였습니다.
Parameter Initialization
신경망 모델의 목적은 손실(Loss)을 최소화하는 과정, 즉 파라미터 최적화(Parameter optimization)입니다. 이를 위해서 손실함수에 대해 경사 하강법을 수행했습니다.
이를테면, 어떤 데이터셋의 손실 함수 그래프가 아래와 같이 생겼다고 해보겠습니다. 그런데 동일하게 경사 하강법을 따라서 내려가더라도 도달하는 최저점이 다른 것을 볼 수 있습니다.
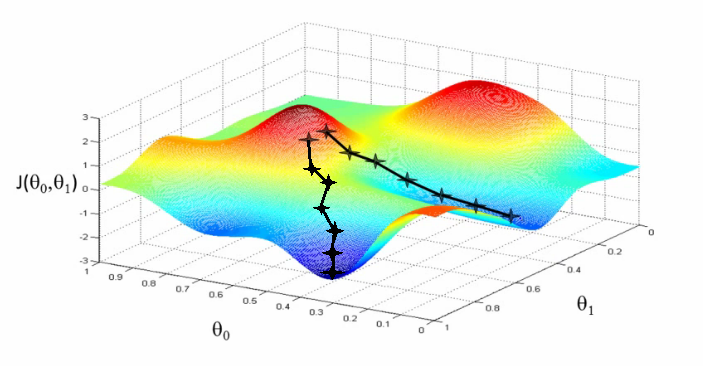
이미지 출처 : medium.com/coinmonks
만약에 오른쪽 봉우리 어딘가에서 시작한다면 같은 지점에서 시작한다면 아래 새로 생긴 경로를 따라서 학습될 수도 있겠지요. 이 경로를 따라 나온 최저점은 앞선 두 결과의 최저점보다 훨씬 더 큽니다. 제대로 최적화되지 못한 것이지요.

이처럼 첫 위치를 잘 정하는 것도 좋은 학습을 위한 조건 중 하나입니다. 이 때문에 학습 시작 시점의 가중치를 잘 정해주어야 하지요. 상황에 맞는 적절한 가중치 초기화(Weight initialization)방법을 사용하게 됩니다. 고성능의 신경망 모델을 구축하기 위해 꼭 필요한 작업이지요. 그렇다면 가중치 초기화 방법에는 어떤 것이 있을까요?
Zero initialization
가장 먼저 떠오르는 생각은 “모든 파라미터 값을 0으로 놓고 시작하면 되지 않을까?” 입니다. 하지만 이는 너무나도 단순한 생각입니다. 좀 더 자세히 말하자면 신경망의 파라미터가 모두 같아서는 안됩니다.
파라미터의 값이 모두 같다면 역전파(Back propagation)를 통해서 갱신하더라도 모두 같은 값으로 변하게됩니다. 신경망 노드의 파라미터가 모두 동일하다면 여러 개의 노드로 신경망을 구성하는 의미가 사라집니다. 결과적으로 층마다 한 개의 노드만을 배치하는 것과 같기 때문이지요. 그래서 초깃값은 무작위로 설정해야 합니다.
Random Initialization
파라미터에 다른 값을 부여하기 위해서 가장 쉽게 생각해 볼 수 있는 방법은 확률분포를 사용하는 것이지요. 정규분포를 이루는 값을 각 가중치에 배정하여 모두 다르게 설정할 수 있습니다. 표준편차를 다르게 설정하면서 정규분포로 가중치를 초기화한 신경망의 활성화 함수 출력 값을 시각화해보겠습니다. 신경망은 100개의 노드를 5층으로 쌓았습니다.
먼저 표준편차가 $1$인 케이스를 알아보겠습니다. 활성화 함수로는 시그모이드(로지스틱) 함수를 사용하였습니다.

그림으로 보면 활성화 함수로부터 0과 1에 가까운 값만 출력되는 것을 볼 수 있습니다. 활성화 값이 0과 1에 가까울 때 로지스틱 함수의 미분값은 거의 0에 가깝습니다. 이렇게 되면 학습이 일어나지 않는 기울기 소실(Gradient vanishing) 현상이 발생하게 됩니다. 그렇다면 이렇게 값이 양 극단으로 치우치지 않도록 표준편차를 줄여보겠습니다. 아래는 표준편차를 $0.01$ 인 정규분포로 가중치를 초기화한 뒤에 활성화 함수의 출력값을 시각화한 것입니다.

하고자 했던 대로 기울기 소실 효과는 발생하지 않았습니다. 하지만 대부분의 출력값이 $0.5$ 주변에 위치하고 있네요. Zero initialization에서도 말했던 것처럼 모든 노드의 활성화 함수의 출력값이 비슷하면 노드를 여러 개로 구성하는 의미가 사라지게 됩니다.
Xavier Initialization
사비에르 초기화(Xavier initialization)는 위에서 발생했던 문제를 해결하기 위해 고안된 초기화 방법입니다. 사비에르 초기화에서는 고정된 표준편차를 사용하지 않습니다. 이전 은닉층의 노드 수에 맞추어 변화시킵니다. 이전 은닉층의 노드의 개수가 $n$ 개이고 현재 은닉층의 노드가 $m$ 개일 때, $\frac{2}{\sqrt{n+m}}$ 을 표준편차로 하는 정규분포로 가중치를 초기화합니다.
이전과 동일한 신경망에 가중치를 사비에르 초깃값으로 초기화한 뒤 활성화 값 그래프가 어떻게 나오는지 시각화 해보겠습니다.

활성값이 이전 두 방법보다 훨씬 더 고르게 퍼져있음을 볼 수 있습니다. 층마다 노드 개수를 다르게 설정하더라도 이에 맞게 가중치가 초기화되기 때문에 고정된 표준편차를 사용하는 것보다 훨씬 더 강건(Robust)합니다. 사비에르 초기화는 논문을 발표했던 사비에르 글로로트(Xavier Glorot)의 이름을 따서 만들어졌는데요. 성을 따서 글로로트 초기화로 불리기도 합니다. 텐서플로우와 파이토치에서는 각각 아래와 같이 사비에르 초기화를 적용할 수 있습니다.
# TensorFlow
tf.keras.initializers.GlorotNormal()
# PyTorch
torch.nn.init.xavier_normal_()
He Initialization
He 초기화(He Initialization)는 ReLU함수를 활성화 함수로 사용할 때 추천되는 초기화 방법입니다. 컴퓨터 비전(Computer vision) 분야의 대표적인 Pre-trained 모델인 VGG도 활성화 함수로 ReLU를 사용하고 있는데요. 그렇기 때문에 He 초기화를 적용하고 있습니다. He 초기화는 $\sqrt{\frac{2}{n}}$ 를 표준편차로 하는 정규분포로 초기화합니다.
아래는 활성화 함수가 ReLU 함수인 5층 신경망에서 사비에르 초기화를 적용했을 때 활성값이 어떻게 변하는 지를 나타낸 그래프입니다.

첫 번째 층에서는 활성화 값이 골고루 분포되어 있지만 층이 깊어질수록 분포가 치우치는 것을 볼 수 있습니다. 만약 층이 더 깊어진다면 거의 모든 값이 $0$에 가까워지면서 기울기 소실이 발생하게 됩니다. 그렇다면 He 초기화를 사용했을 때는 활성값이 어떻게 변하는지 알아보겠습니다.

층이 깊어지더라도 모든 활성값이 고른 분포를 보이는 것을 알 수 있습니다. 사비에르 초기화와 마찬가지로 He 초기화 역시 카이밍 히(Kaiming He)의 성을 따서 지어졌습니다. 이름을 따서 카이밍 초기화로 부르기도 합니다. 텐서플로우와 파이토치에서는 각각 아래와 같이 He 초기화를 적용할 수 있습니다.
# TensorFlow
tf.keras.initializers.HeNormal()
# PyTorch
torch.nn.init.kaiming_normal_()
Choice
지금까지 살펴본 것처럼 사용하는 활성화 함수에 따라 적절한 초기화 방법이 달라집니다. 일반적으로 활성화 함수가 시그모이드 함수일 때는 사비에르 초기화를, ReLU류의 함수일 때는 He 초기화를 사용합니다. 하지만 가중치 초기화 방법은 이외에도 많으며 절대적인 답이 정해져 있는 것은 아닙니다.
이번 게시물은 “밑바닥부터 시작하는 딥러닝”과 “Weight Initialization Techniques in Neural Networks”를 참조하여 작성하였습니다.
Parameter Initialization
신경망 모델의 목적은 손실(Loss)을 최소화하는 과정, 즉 파라미터 최적화(Parameter optimization)입니다. 이를 위해서 손실함수에 대해 경사 하강법을 수행했습니다.
이를테면, 어떤 데이터셋의 손실 함수 그래프가 아래와 같이 생겼다고 해보겠습니다. 그런데 동일하게 경사 하강법을 따라서 내려가더라도 도달하는 최저점이 다른 것을 볼 수 있습니다.
이미지 출처 : medium.com/coinmonks
만약에 오른쪽 봉우리 어딘가에서 시작한다면 같은 지점에서 시작한다면 아래 새로 생긴 경로를 따라서 학습될 수도 있겠지요. 이 경로를 따라 나온 최저점은 앞선 두 결과의 최저점보다 훨씬 더 큽니다. 제대로 최적화되지 못한 것이지요.
이처럼 첫 위치를 잘 정하는 것도 좋은 학습을 위한 조건 중 하나입니다. 이 때문에 학습 시작 시점의 가중치를 잘 정해주어야 하지요. 상황에 맞는 적절한 가중치 초기화(Weight initialization)방법을 사용하게 됩니다. 고성능의 신경망 모델을 구축하기 위해 꼭 필요한 작업이지요. 그렇다면 가중치 초기화 방법에는 어떤 것이 있을까요?
Zero initialization
가장 먼저 떠오르는 생각은 “모든 파라미터 값을 0으로 놓고 시작하면 되지 않을까?” 입니다. 하지만 이는 너무나도 단순한 생각입니다. 좀 더 자세히 말하자면 신경망의 파라미터가 모두 같아서는 안됩니다.
파라미터의 값이 모두 같다면 역전파(Back propagation)를 통해서 갱신하더라도 모두 같은 값으로 변하게됩니다. 신경망 노드의 파라미터가 모두 동일하다면 여러 개의 노드로 신경망을 구성하는 의미가 사라집니다. 결과적으로 층마다 한 개의 노드만을 배치하는 것과 같기 때문이지요. 그래서 초깃값은 무작위로 설정해야 합니다.
Random Initialization
파라미터에 다른 값을 부여하기 위해서 가장 쉽게 생각해 볼 수 있는 방법은 확률분포를 사용하는 것이지요. 정규분포를 이루는 값을 각 가중치에 배정하여 모두 다르게 설정할 수 있습니다. 표준편차를 다르게 설정하면서 정규분포로 가중치를 초기화한 신경망의 활성화 함수 출력 값을 시각화해보겠습니다. 신경망은 100개의 노드를 5층으로 쌓았습니다.
먼저 표준편차가 $1$인 케이스를 알아보겠습니다. 활성화 함수로는 시그모이드(로지스틱) 함수를 사용하였습니다.
그림으로 보면 활성화 함수로부터 0과 1에 가까운 값만 출력되는 것을 볼 수 있습니다. 활성화 값이 0과 1에 가까울 때 로지스틱 함수의 미분값은 거의 0에 가깝습니다. 이렇게 되면 학습이 일어나지 않는 기울기 소실(Gradient vanishing) 현상이 발생하게 됩니다. 그렇다면 이렇게 값이 양 극단으로 치우치지 않도록 표준편차를 줄여보겠습니다. 아래는 표준편차를 $0.01$ 인 정규분포로 가중치를 초기화한 뒤에 활성화 함수의 출력값을 시각화한 것입니다.
하고자 했던 대로 기울기 소실 효과는 발생하지 않았습니다. 하지만 대부분의 출력값이 $0.5$ 주변에 위치하고 있네요. Zero initialization에서도 말했던 것처럼 모든 노드의 활성화 함수의 출력값이 비슷하면 노드를 여러 개로 구성하는 의미가 사라지게 됩니다.
Xavier Initialization
사비에르 초기화(Xavier initialization)는 위에서 발생했던 문제를 해결하기 위해 고안된 초기화 방법입니다. 사비에르 초기화에서는 고정된 표준편차를 사용하지 않습니다. 이전 은닉층의 노드 수에 맞추어 변화시킵니다. 이전 은닉층의 노드의 개수가 $n$ 개이고 현재 은닉층의 노드가 $m$ 개일 때, $\frac{2}{\sqrt{n+m}}$ 을 표준편차로 하는 정규분포로 가중치를 초기화합니다.
이전과 동일한 신경망에 가중치를 사비에르 초깃값으로 초기화한 뒤 활성화 값 그래프가 어떻게 나오는지 시각화 해보겠습니다.
활성값이 이전 두 방법보다 훨씬 더 고르게 퍼져있음을 볼 수 있습니다. 층마다 노드 개수를 다르게 설정하더라도 이에 맞게 가중치가 초기화되기 때문에 고정된 표준편차를 사용하는 것보다 훨씬 더 강건(Robust)합니다. 사비에르 초기화는 논문을 발표했던 사비에르 글로로트(Xavier Glorot)의 이름을 따서 만들어졌는데요. 성을 따서 글로로트 초기화로 불리기도 합니다. 텐서플로우와 파이토치에서는 각각 아래와 같이 사비에르 초기화를 적용할 수 있습니다.
# TensorFlow
tf.keras.initializers.GlorotNormal()
# PyTorch
torch.nn.init.xavier_normal_()
He Initialization
He 초기화(He Initialization)는 ReLU함수를 활성화 함수로 사용할 때 추천되는 초기화 방법입니다. 컴퓨터 비전(Computer vision) 분야의 대표적인 Pre-trained 모델인 VGG도 활성화 함수로 ReLU를 사용하고 있는데요. 그렇기 때문에 He 초기화를 적용하고 있습니다. He 초기화는 $\sqrt{\frac{2}{n}}$ 를 표준편차로 하는 정규분포로 초기화합니다.
아래는 활성화 함수가 ReLU 함수인 5층 신경망에서 사비에르 초기화를 적용했을 때 활성값이 어떻게 변하는 지를 나타낸 그래프입니다.
첫 번째 층에서는 활성화 값이 골고루 분포되어 있지만 층이 깊어질수록 분포가 치우치는 것을 볼 수 있습니다. 만약 층이 더 깊어진다면 거의 모든 값이 $0$에 가까워지면서 기울기 소실이 발생하게 됩니다. 그렇다면 He 초기화를 사용했을 때는 활성값이 어떻게 변하는지 알아보겠습니다.
층이 깊어지더라도 모든 활성값이 고른 분포를 보이는 것을 알 수 있습니다. 사비에르 초기화와 마찬가지로 He 초기화 역시 카이밍 히(Kaiming He)의 성을 따서 지어졌습니다. 이름을 따서 카이밍 초기화로 부르기도 합니다. 텐서플로우와 파이토치에서는 각각 아래와 같이 He 초기화를 적용할 수 있습니다.
# TensorFlow
tf.keras.initializers.HeNormal()
# PyTorch
torch.nn.init.kaiming_normal_()
Choice
지금까지 살펴본 것처럼 사용하는 활성화 함수에 따라 적절한 초기화 방법이 달라집니다. 일반적으로 활성화 함수가 시그모이드 함수일 때는 사비에르 초기화를, ReLU류의 함수일 때는 He 초기화를 사용합니다. 하지만 가중치 초기화 방법은 이외에도 많으며 절대적인 답이 정해져 있는 것은 아닙니다.
Comments